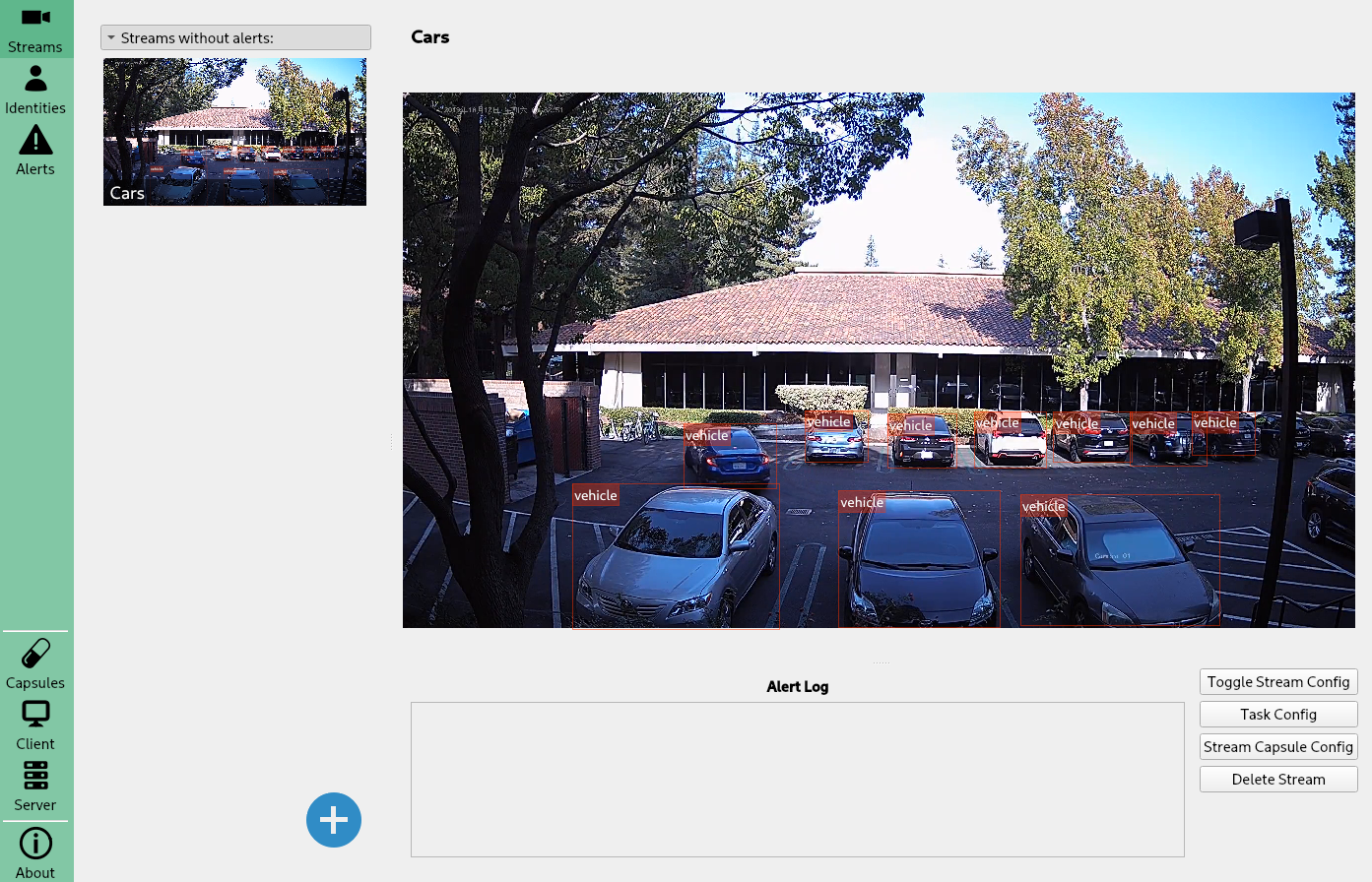
Creating an OpenVINO Object Detector Capsule¶
Introduction¶
This tutorial will guide you through encapsulating an OpenVINO object detector model. For this tutorial, we will be using the person-vehicle-bike-detection-crossroad-1016 model from the Open Model Zoo, but the concepts shown here will work for all OpenVINO object detectors. You can find the complete capsule on the Capsule Zoo.
See the previous tutorial for information on setting up a development environment.
Getting Started¶
We will start by creating a directory where all our capsule code and model
files will reside. By convention, capsule names start with a small description
of the role the capsule plays, followed by the kinds of objects they operate
on, and finally some kind of differentiating information about the capsule's
intended use or implementation. We will name this capsule
detector_person_vehicle_bike_openvino and create a directory with that name.
Then, we will add a meta.conf file, which will let the application loading
the capsule know what version of the OpenVisionCapsules API this capsule
requires. OpenVINO support was significantly improved in version 0.2.x, so we
will require at least that minor version of the API:
[about]
api_compatibility_version = 0.3
We will also add the weights and model files into this directory so they can be loaded by the capsule. After these steps, your data directory should look like this:
your_data_directory
├── volumes
└── capsules
└── detector_person_vehicle_bike_openvino
├── person-vehicle-bike-detection-crossroad-1016-fp32.bin
├── person-vehicle-bike-detection-crossroad-1016-fp32.xml
└── meta.conf
The Capsule Class¶
Next, we will define the Capsule class. This class provides the application
with information about your capsule. The class must be named Capsule and
the file it is defined in must be named capsule.py. We will create that
file in the capsule directory with the following contents:
from vcap import (
BaseCapsule,
NodeDescription,
DeviceMapper,
common_detector_options
)
from .backend import Backend
class Capsule(BaseCapsule):
name = "detector_person_vehicle_bike_openvino"
description = ("OpenVINO person, vehicle, and bike detector. Optimized "
"for surveillance camera scenarios.")
version = 1
device_mapper = DeviceMapper.map_to_openvino_devices()
input_type = NodeDescription(size=NodeDescription.Size.NONE)
output_type = NodeDescription(
size=NodeDescription.Size.ALL,
detections=["vehicle", "person", "bike"])
backend_loader = lambda capsule_files, device: Backend(
model_xml=capsule_files[
"person-vehicle-bike-detection-crossroad-1016-fp32.xml"],
weights_bin=capsule_files[
"person-vehicle-bike-detection-crossroad-1016-fp32.bin"],
device_name=device
)
options = common_detector_options
In this file, we have defined a Capsule class that subclasses from
BaseCapsule and defines some fields. The name field reflects the name
of the capsule directory and the description field is a short,
human-readable description of the capsule's purpose. The other fields are a bit
more complex, so let's break each one down.
version = 1
This is the capsule's version (not to be confused with the version of the
OpenVisionCapsules API defined in the meta.conf). Since this is the first
version of our capsule, we'll start it at 1. The version field can be used as a
way to distinguish between different revisions of the same capsule. This field
has no semantic meaning to BrainFrame and can be incremented as the capsule
developer sees fit. Some developers may choose to increment it with every
iteration; others only when significant changes have occurred.
device_mapper = DeviceMapper.map_to_openvino_devices()
This device mapper will map our backends to any available OpenVINO-compatible devices, like the Intel Neural Compute Stick 2 or the CPU.
input_type = NodeDescription(size=NodeDescription.Size.NONE)
This detector capsule requires no output from any other capsules in order to run. All it needs is the video frame.
output_type = NodeDescription(
size=NodeDescription.Size.ALL,
detections=["vehicle", "person", "bike"])
This detector provides "vehicle", "person", and "bike" detections as output and is expected to detect all vehicles, people, and bikes in the video frame.
backend_loader = lambda capsule_files, device: Backend(
model_xml=capsule_files[
"person-vehicle-bike-detection-crossroad-1016-fp32.xml"],
weights_bin=capsule_files[
"person-vehicle-bike-detection-crossroad-1016-fp32.bin"],
device_name=device
)
Here we define a lambda function that creates an instance of a Backend class with the model and weights files, as well as the device this backend will run on. We will define this Backend class in the next section.
options = common_detector_options
We give this capsule some basic options that are common among most detector capsules.
With this new capsule.py file added, your capsule directory should look
like this:
your_data_directory
├── volumes
└── capsules
└── detector_person_vehicle_bike_openvino
├── capsule.py
├── person-vehicle-bike-detection-crossroad-1016-fp32.bin
├── person-vehicle-bike-detection-crossroad-1016-fp32.xml
└── meta.conf
The Backend Class¶
Finally, we will define the Backend class. This class defines how the
capsule runs analysis on video frames. An instance of this class will be
created for every device the capsule runs on. The Backend class doesn't
have to be defined in any specific location, but we will add it to a new file
called backend.py with the following contents:
from typing import Dict
import numpy as np
from vcap import (
DETECTION_NODE_TYPE,
OPTION_TYPE,
BaseStreamState)
from vcap_utils import BaseOpenVINOBackend
class Backend(BaseOpenVINOBackend):
label_map: Dict[int, str] = {1: "vehicle", 2: "person", 3: "bike"}
def process_frame(self, frame: np.ndarray,
detection_node: DETECTION_NODE_TYPE,
options: Dict[str, OPTION_TYPE],
state: BaseStreamState) -> DETECTION_NODE_TYPE:
input_dict, resize = self.prepare_inputs(frame)
prediction = self.send_to_batch(input_dict).result()
detections = self.parse_detection_results(
prediction, resize, self.label_map,
min_confidence=options["threshold"])
return detections
Our Backend class subclasses from BaseOpenVINOBackend. This backend
handles loading the model into memory from the given files, implements batching,
and provides utility methods that make writing OpenVINO backends easy. All we
need to do is define the process_frame method. Let's take a look at each
call in the method body.
input_dict, resize = self.prepare_inputs(frame)
This line prepares the given video frame to be fed into the model. The video frame is resized to fit in the model and formatted in the way the model expects. Also provided is a resize object, which contains the necessary information to map the resulting detections to the coordinate system of the originally sized video frame.
This method assumes that your OpenVINO model expects images in the format (num_channels, height, width) and expects the frame to be in a dict with the key being the network's input name. Ensure that your model follows this convention before using this method.
prediction = self.send_to_batch(input_dict).result()
Next, the input data is sent into the model for batch processing. The call to
get causes the backend to block until the result is ready. The results
are objects with raw OpenVINO prediction information.
detections = self.parse_detection_results(
prediction, resize, self.label_map,
min_confidence=options["threshold"])
return detections
Finally, the results go through post-processing. Detections with a low confidence are filtered out, raw class IDs are converted to human-readable class names, and the results are scaled up to fit the size of the original video frame.
Wrapping Up¶
With the meta.conf, Capsule class, Backend class, and model files, the capsule is now complete! Your data directory should look something like this:
your_data_directory
├── volumes
└── capsules
└── detector_person_vehicle_bike_openvino
├── backend.py
├── capsule.py
├── person-vehicle-bike-detection-crossroad-1016-fp32.bin
├── person-vehicle-bike-detection-crossroad-1016-fp32.xml
└── meta.conf
When you restart BrainFrame, your capsule will be packaged into a .cap file
and initialized. You'll see its information on the BrainFrame client.

Load up a video stream to see detection results.